Una vez construido un modelo de simulación es necesario ejecutar un Análisis Resultados para garantizar la robustez de del modelo y la validez de los hallazgos.
El análisis de resultados consiste en ejecutar múltiples repeticiones de un experimento haciendo o no cambios a una o varias variables de manera que se describa el comportamiento general del modelo y se identifiquen los patrones de los resultados dados diferentes valores de las variables de entrada. Si estas repeticiones se hacen con cambios incrementales en las variables de entrada, se conoce como Análisis de Sensibilidad. Si las variables de entrada tienen una distribución de probabilidad asociada se puede generar una secuencia combinada basada en dicha distribución, lo que se conoce como Monte Carlo. Cuando las variaciones son estratificadas (escalas uniformes) sin importar la distribución asociada se conoce como Variación de Parámetros.
AnyLogic en su versión PLE permite realizar Variación de Parámetros y Optimización. Versiones más avanzadsa como la versión profesional permiten además realizar Comparación de Experimentos, Monte Carlo, Análisis de Sensibilidad, Calibración y Experimentos personalizados (ver imagen).

Siendo la variación de parámetros el único tipo de experimento disponible en la versión PLE para la fase post-simulación a continuación se explica cómo hacer muestreo y análisis de resultados usando este módulo y algunas maneras de implementar rutinas que incrementen su funcionalidad.
Al construir un modelo de simulación se debe establecer todo el espectro y distribución de las variables de entrada (parámetros). Para ello utilizamos muestreo y análisis estadístico. Esta parte pre-simulación será tratada en otro post.
Al finalizar el modelo, se deben ejecurar múltiples repeticiones con diferentes valores aleatorios y parámetros para establecer el rango total de salida. Idealmente se deben simular todos los escenarios posibles, sin embargo, en muchas ocasiones el número total de escenarios es tan alto que simular el espectro completo tarda demasiado. En estos casos es recomendable utilizar muestreo sobre los parámetros para elegir combinaciones estadísticamente representativas.
A continuación se explican los diferentes tipos de muestreo.
Tipos de Muestreo
Muestreo Aleatorio: Consiste en generar muestras eligiendo números al azar sobre la distribución de probabilidad acumulada. Esta técnica requiere un elevado número de muestras para conseguir una representación adecuada de la variable en estudio (cientos o miles de repeticiones).
Muestreo Estratificado: Consiste en segmentar la variable en grupos o estratos y elegir valores aleatorios al interior de cada sub-grupo para la simulación. Los estratos son generados a partir de información típica de la distribución observada. Requiere también de un elevado número de repeticiones aunque menor que el muestreo aleatorio.
Muestreo por Hipercubo Latino: Consiste en asignar distribuciones de probabilidad a cada variable de entrada y distribuir cada una en un número de intervalos equiprobables. Luego se eligen valores al interior de cada grupo y se combinan con las demás dimensiones de las otras variables, para obtener vectores completamente independientes y aleatorios como entradas del modelo. Dado que cada muestra es independiente, se requieren menos repeticiones pues se asume que una serie completa de experimentos con esta entrada es estadísticamente independiente.
Un inconveniente típico en este último método es que la representatividad de los resultados solo se puede evaluar luego de ejecutar todos los experimentos y en caso de no ser satisfactoria, se debe volver a empezar aumentando la cantidad de intervalos equiprobables. Una solución a este inconveniente es la utilización del Hipercubo Latino Escalable.
Segmentación
En otras ocasiones no es necesario conocer todo el espectro sino un segmento de él. Si el segmento es contínuo (ejemplo una variable puede distribuirse entre 100 y 200 visitas por hora pero solo se desea evaluar el impacto de mas de 160 visitas al día) se considera como una variación de parámetros con menos combinaciones. Cuando las variaciones son discontinuas y combinadas, es mejor definir los escenarios previamente y luego ejecutar experimentos basados únicamente en la matriz de entrada. En AnyLogic esto se implementa fácilmente utilizando bases de datos o archivos externos.
Implementación en AnyLogic
Una vez se elige un nuevo experimento de tipo variación de parámetros, AnyLogic crea una nueva sesión en blanco donde se define la memoria total a utilizar, el agente de referencia (usualmente Main) y la forma como los parámetros van a interactuar (ver imagen). Estos parámetros pueden ser fijos o variables en un rango, es decir se fija un valor único o el valor inferior y superior, así como el paso (step) para su variación uniforme.

De esta forma, si se tiene un modelo con 10 parámetros de entrada de las cuales 2 se planean fijas y 8 variables con 10 pasos por cada una, se deben tener al menos 100 millones de experimentos para cubrir una sola repetición de todas las simulaciones.
Ejemplo
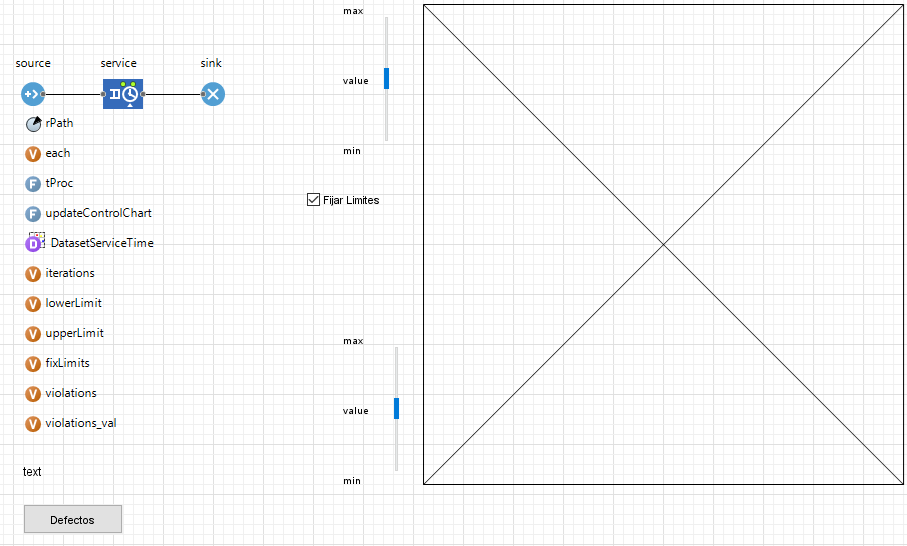
Un ejemplo es el siguiente modelo en el cuál un taller cuenta con cuatro estaciones de trabajo en serie, cada una con un buffer de entrada con capacidad limitada. Las estaciones cuentan con un tiempo de procesamiento tn (9, 12, 8 y 14 minutos respectivamente) distribuido triangularmente más o menos 10% (ver imagen del modelo).

Luego de haber ingresado 1000 unidades al sistema el modelo se detiene y verifica los indicadores claves de rendimiento. Estos son:
- % de piezas completadas
- Piezas en proceso promedio (WIP)
- Tiempo de ciclo promedio
- Tiempo total de operación del taller
- Diferencia promedio de la utilización del mayor y menor buffer
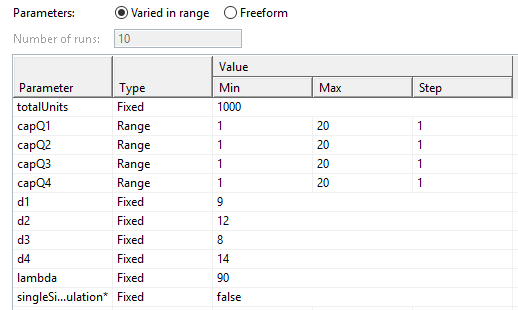
Si suponemos que las capacidades de cada buffer pueden variar entre 1 y 20 unidades lo que representa 20 pasos ya que los variaciones son discretas, se cuenta en total con 160,000 diferentes configuraciones para evaluar todo el espacio (sin réplica).
Para comprobar esto creamos un experimento tipo variación de parámetros y asignamos los siguientes valores (ver imagen).
Hacemos click en Create default UI para crear la interfaz. Luego añadimos 5 estadísticas locales (statComplete, statWIP, statCycleTime, statTotalTime, statDiffQ) en las cuales guardaremos el resultado de cada experimento así como tres histogramas (WIP, tiempo de ciclo y tiempo total).
En la sección indicando qué hacer luego de cada simulación (After simulation run) añadimos el siguiente código:
|
|
statComplete.add((double)root.sink.count()/(double)root.totalUnits*100); statWIP.add(root.statWIP.mean()); statCycleTime.add(root.statCycleTime.mean()); statTotalTime.add(root.totalTime); statDiffQ.add(root.statDiffQ.mean()); dataWIP.add(root.statWIP.mean()); dataCycleTime.add(root.statCycleTime.mean()); dataTotalTime.add(root.totalTime); |
Y finalmente ejecutamos el experimento (ver imagen inferior).

Como se puede observar ejecutar 160 mil experimentos tomó cerca de 8 minutos (478.1 segundos), y los estadísticos permiten establecer que:
- El % de copletado se encuentra entre 91.6 y 99.2 con media de 95.4%
- El WIP entre 0.02 y 70.2 con media de 36.4 unidades
- El tiempo de ciclo entre 112.2 y 1,077.4 con media de 613.8 minutos
- El tiempo total de operación entre 12,823 y 13,998 con media de 13,395 minutos
- La diferencia promedio de utilización de buffers entre 0.4% y 94.9% con media de 37.9%
Según se requiera se pueden crear experimentos específicos de optimización que arrojen la configuración indicada para por ejemplo minimizar el tiempo total de ciclo o minimizar el tiempo total de operación o minimizar el trabajo en proceso (otros post se dedicarán a la creación de experimentos de optimización).
A continuación explicaremos dos formas de realizar el muestreo de manera que el tiempo total de experimentación se reduzca.
Método Alternativo 1: Hipercubo usando R y AnyLogic
Creamos un hipercubo latino utilizando R y transferimos estos valores a AnyLogic para ejecutar específicamente simulaciones de estas configuraciones.
En primer lugar creamos un nuevo experimento de tipo variación de parámetros. Esta vez no asignamos variabilidad a los parámetros de entrada (ver imagen). Creamos la interfaz haciendo click en Create default UI.

Un inconveniente que tiene esta técnica es que la cantidad de experimentos (dimensiones del cubo) son definidas a través de la cantidad de réplicas (o usando la forma libre), en este caso escogemos un total de 2000 experimentos para representar el espacio total de 160,000 (representando un 1.25% del total de la población).
A continuación cargamos la librería RCaller y la importamos al experimento. Así mismo definimos las acciones a realizar antes y después de cada simulación pasar los parámetros y capturar las estadísticas (ver imágen siguiente).

Al igual que en la variación de parámetros, en este experimentos creamos cinco estadísticos y tres histogramas.
Adicionalmente creamos tres variables: totalExperimentos (int), dimensions (int) e hypercube (int[][]). Finalmente creamos una función llamada getHyperCube con el siguiente código:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
try { RCaller caller = new RCaller(); RCode code = new RCode(); caller.setRscriptExecutable("C:/Program Files/Microsoft/MRO/R-3.2.4/bin/x64/Rscript.exe"); code.clear(); code.R_require("lhs"); code.addRCode("a<-randomLHS(" + dimensions + ", 4)"); code.addRCode("a<-round(a*15+1,0)"); caller.setRCode(code); caller.runAndReturnResult("a"); double[][] d = caller.getParser().getAsDoubleMatrix("a"); for(int i=0; i<dimensions; i++){ for(int j=0; j<4; j++){ hypercube[i][j]=(int)d[i][j]; } } } catch (Exception e) { System.out.println(e.toString()); } |
Esta función se ejecuta al inicio de toda la serie de experimentos para crear el hipercubo en R (utilizando el paquete lhs) e importarlo a AnyLogic para almacenarlo en la variable local hypercube. Este hypercubo en realidad es una matriz donde cada fila representa la configuración de los buffer de cada experimento a correr.

Al ejecutar el experimento encontramos:
- El tiempo total de simulación fue de tan solo 21 segundos (23 veces más rápido que el experimento original)
- El % de copletado se encuentra entre 93.4 y 99.0 con media de 96.1%
- El WIP entre 2 y 54 con media de 29 unidades
- El tiempo de ciclo entre 138.6 y 867.59 con media de 511.9 minutos
- El tiempo total de operación entre 13,061 y 13,947 con media de 13,508 minutos
- La diferencia promedio de utilización de buffers entre 1.5% y 93.2% con media de 28.3%
Si bien las distribuciones no reflejan los mismos límites superiores e inferiores de la variación de parámetros anterior, los valores hallados se aproximan bastante, con un tiempo de simulación 23 veces inferior. Esta técnica es particularmente útil cuando se cuenta con capacidad limitada de computación y experimentos complejos donde el espectro completo puede tomar días enteros en ser simulado por tanto una muestra con resultados similares en menor tiempo es muy necesaria.
Método Alternativo 2: Segmentación
En este caso asumimos que solo deseamos simular las siguientes configuraciones:
- Buffer 1: variando de 5 a 15 (step=1)
- Buffer 2: solo puede ser 1, 5, 10 o 15
- Buffer 3: siempre 5
- Buffer 4: valores pares de 2 a 20
En este caso el total de experimentos a realizar es 440 (11*4*1*10).
Creamos entonces un experimento tipo variación de parámetros de forma libre con 440 repeticiones (ver imagen) y añadimos un archivo de Excel donde hemos creado previamente las 440 configuraciones.

En las acciones antes y después creamos el siguiente código que permite leer el archivo de Excel y llenar la variable local hypercube con todas las configuraciones requeridas. Adicionalmente capturamos las estadísticas de rendimiento al finalizar cada experimento.

Ejecutamos el experimento.

Esta vez el experimento tomó solamente 2.3 segundos (sin repetición). El usuario puede repetir varias veces la matriz Excel y aumentar el número de experimentos en AnyLogic para añadir repeticiones.
El modelo soporte, la librería RCaller y el archivo Excel pueden ser descargados en el siguiente link.
Descarga